
That Substack about N1-methylpseudouridines and frameshifting
Another predictable harm...

“All of the harms from the COVID-19 injectable products were predictable, and preventable.”
Jessica Rose, PhD
On the heels of the latest Nature publication entitled: N1-methylpseudouridylation of mRNA causes +1 ribosomal frameshifting, published December 6, 20231, came a comment from David Speicher, David Wiseman, Kevin McKernan, Maria Gutschi and myself entitled: Ribosomal frameshifting and misreading of mRNA in COVID-19 vaccines produces “off-target”proteins and immune responses eliciting safety concerns: Comment on UK study by Mulroney et al. We were able to pen this response very quickly since we had already collectively predicted this problem.
The authors write that N1-methylpseudouridine affects the fidelity of mRNA translation via ribosome stalling that induces frameshifting. Frameshifting results in the production multiple, unique and potentially aberrant proteins.
The modified mRNAs for use in the COVID-19 products were codon-optimized for maximal protein expression in humans. Codon optimization, or synonymous codon replacement, rests on the idea that one can induce mutations throughout a gene of interest (like spike) based on an organism’s (like humans) codon usage bias, to increase translational efficiency and protein expression without altering the sequence of the protein.2 But, it is well-known that codon-optimization can lead to protein conformation, folding and stability problems.
Codon optimization could affect protein conformation, folding and stability, change post-translational modification sites and even affect protein function. Different rates of translation by different tRNAs, including those that exhibit wobble base-pairing (a tRNA that can recognize multiple synonymous codons) may actually be critical for determining the rate of translation. The ribosome may slow and pause during elongation which may actually be necessary for proper protein folding. Therefore, codon optimization may disrupt the fine-tuned timing of translation and ultimately protein function.34
Codon optimization can also lead to misfolding of mRNAs due to increased Guanine/Cytosine (GC content). Please read McKernan et al.’s preprint, Xia et al.’s paper and Seneff et al.’s paper to learn more about potential problems relating to codon optimization and GC content changes. The latter group write:
Synonymous codon replacement also results in a change in the multifunctional regulatory and structural roles of resulting proteins.56
There is, in fact, a significant enrichment of GC content (17% and 25% enrichments as per Pfizer and Moderna, respectively, as compared to SARS-CoV-2) as a result of the codon optimization that was done, and this can lead to “dysregulation of the G4-RNA-protein binding system and a wide range of potential disease-associated cellular pathologies including suppression of innate immunity, neurodegeneration, and malignant transformation”7. Increased GC content significantly alters mRNA secondary structure as well,89 and this can also lead to ribosomal pausing or stalling.
N.B. Ehden Biber also wrote a great article about the pitfalls of codon optimization that you can read here.
In a Nature article published in 2011 entitled: “Breaking the silence”10, the author writes on the potential danger of fiddling with codons in therapeutic proteins whereby it “could have unpredictable effects on people’s health”. She points to a study where the authors show that a synonymous codon change found in the most common form of cystic fibrosis results in mRNA misfolding.11 (Keep this in mind.) She also points out that in the context of the multi-drug resistance 1 gene (MDR1) (the gene that encodes P-glycoprotein), that a codon change may interfere with the pauses that characterize RNA passing through the ribosome, thereby changing how the growing amino acid chain folds.12 But perhaps the most timely and spine-tingly relevant statement in this article is found at the end, and I quote:
At the moment, companies developing recombinant therapies must verify that the DNA sequence designed by their scientists is the one that’s producing their proteins, but they aren’t required to note how different that is from the native genetic code. “We do not have any guidance with regard to the [DNA] sequence,” Kimchi-Sarfaty notes. That’s one piece of data that could be tracked by the system she is proposing. Such knowledge, in turn, could ultimately help define better strategies for optimization and possibly even make biologic drugs safer for people. Alla Katsnelson
I wonder if the FDA ever took her advice to track the differences in codons and the resulting potential adverse effects?
In addition to our comment on the Nature paper, a University of Cambridge write-up entitled: Researchers redesign future mRNA therapeutics to prevent potentially harmful immune responses was penned. They make it clear that the most relevant conclusion from the Nature paper is that we can make more products similarly insanely dangerous as the ones pumped into billions of bodies because we can simply ‘reduce the production of frameshifted products’ by ‘synonymous targeting of slippery sequences’. Well of course! Now that we know that billions of people’s cells might be making aberrant proteins, for unknown periods of time, we can simply sweep these people under the rug, ‘fix’ the product, and keep on makin’ money.
Let’s go slidin’ down the slippery sequence slope of gene therapy straight to the Gates of hell.
The manufacturers might have thought to explore options to prevent potentially harmful responses from their products prior to injecting billions of people with them. It is criminal that these products continue to be forced onto newborns and infants by mandate, to this day.
On the subject of messing with Mother Nature, perhaps no one said it better than Allan Drummond - an evolutionary cell biologist at the University of Chicago: “Please do not monkey with these sites; they are optimized for some reason”, in reference to codon bias in mammals.
After such a long introduction, I hope that you still have stamina to keep reading. My goal for this article is to make it easy for anyone to explain to anyone else this latest confirmation in the Nature paper: that the modified bases in the COVID-19 mRNA products result in ribosomal frameshifting, and that this can, and likely does, lead to aberrant protein production and misfolding of proteins.13
Grab a coffee, or a bottle of wine, and bear with me.

Fun fact: Pseudouridines (Ψs) are a normal and essential part of our biology. They have been called the 5th nucleotide, in fact, and “are a ubiquitous constituent of structural RNA (transfer, ribosomal, small nuclear (snRNA) and small nucleolar), and present in coding RNA, across the three phylogenetic domains of life”14 and “accounts for about 1.4% of all bases in human rRNAs.”15
Background
On DNA and RNA
Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) are the reasons for all things biology. They differ primarily in function whereby DNA stores genetic information while RNA converts genetic information for use in protein production in complex life forms. They also differ in 3 main other ways: 1. their sugar backbones (with phosphates - aka: the phosphodiester backbone) - deoxyribose for DNA and ribose for RNA, 2. bases: Thymine (T) for DNA and Uracil (U) for RNA, and 3. stranded-ness: double-stranded for DNA and single-stranded for RNA. RNA can fold over onto itself, as is the case with hairpin loops, for example, to assume a ‘double-strandedness’, but, by nature, it is single stranded. N.B. RNAs can misfold as well.
As shown in Figure 2, Adenine (A), Guanine (G), Cytosine (C) and Uracil (U) comprise the nucleobases for RNA whereby Uracil is the demethylated form of Thymine (or Thymine is the methylated form of Uracil). And don’t forget, A base-pairs with U (or T for DNA), and C base-pairs with G, via hydrogen bonding. These are known as the Watson-Crick base pairs.

Focus on RNA
On Uridine
Uridine is the glycosylated form of Uracil, ie: it has a sugar (ribose) attached to it. The sugar, bound to a phosphate, creates the backbone for the bases A, C, G and U that makes up the RNA strand. The sugar bone’s connected to the, phosphate bone. Remember that learning song Dem Bones? The neck bone’s connected to the, knee bone, as it was sung in my family. It’s a wonder I made it out of high school.
Figure 3 below demonstrates the differences between Uracil and Uridine and how the RNA backbone is constructed: it is simply a series of covalently-bonded phosphates and sugars. Incidentally, RNA is negatively charged (polyanion) because of the phosphate groups (which are negatively charged) so the overall charge of the RNA polymer is negative. That’s why those cationic lipids in the COVID-19 injectable products (so very positively charged to the point of being woke) bundle them up so well in those lipid nanoparticles (LNPs).

On Pseudouridine (and N1-methylpseudourdine)
Pseudouridine (Ψ) is a modification of Uridine. In Figure 4, the difference between Uridine and Ψ is shown, whereby the Uridine molecule undergoes a slight change in the presence of pseudouridylase/Ψ-synthase which catalyze a reaction. Basically, Ψ is the flipped version (isomer) of Uridine whereby the Uracil in the Ψ is attached via a carbon-carbon instead of a nitrogen-carbon glycosidic bond.
Ψ is derived from uridine via a base-specific isomerization reaction called pseudouridylation, in which the nucleobase rotates 180° around the N3-C6 axis, resulting in the change of nucleobase-sugar bond (from N1-C1′ bond to C5-C1′ bond). The resulting C-C bond allows the nucleobase to rotate more freely.1617
One of interesting things about Ψs is that they can bind all 4 bases.181920 This is what is referred to as wobble base-pairing as mentioned in one of the above introductory quotes. “While pseudouridine can wobble-pair with bases other than A potentially leading to mistranslated proteins, it is unclear whether this happens with m1Ψ.”21 Remember this point for the coming section.
N1-methyl-Ψ (m1Ψ) is the methylated derivative of Ψ as shown on the right in Figure 3. It is an archaeal transfer RNA (tRNA) component,22 which means its appearance might primarily be by unnatural design. But, since detection methods for Ψ aren’t specific enough to discern between Ψ and m1Ψ, it’s possible that there are more m1Ψs in us than we previously thought.2324
I wonder who ultimately decided that it would be a good idea to bombard people’s cells with truckloads of it, all at once, in the form of an injected codon-optimized modified mRNA wrapped in an LNP?

According to Morais et el., the m1Ψ isn’t promiscuous and pair bonds with A just like unchemically-modified Uridine does.25
On the other hand, N1-methyl-Ψ has a methyl group instead in the N1-position, thus eliminating the extra hydrogen bond donor. Consequently, N1-methyl-Ψ can only use its Watson-Crick face to base-pair with another nucleoside, thus preventing it from wobble-pairing with other nucleotides (G, U, and C).
The subtle differences between these chemically-modified versions of Uridine have substantial effects in terms of stability, functionality, wobble-pairing and melting temperatures. Since the melting temperatures of both Ψs and m1Ψs are higher than for Uridine26, it takes more energy to break the m1Ψ-A bonds once they form thus stabilizing RNA, for example. In effect, m1Ψ and Ψ are stickier than Uridine. Some of the properties of Ψ are summarized in the following quote.
In particular, the presence of Ψ is able to: (i) give greater rigidity to the phosphodiester backbone of the RNA; (ii) stabilize Ψ-A base pairs (compared to that of U-A base pairs) through some effects on base stacking and water coordination, thus affecting RNA structure, spatial conformation and, ultimately, its functional properties; at the same time; (iii) increasing the thermal stability.2728
It has been shown that defects in RNA pseudouridylation29 are associated with human disease, which demonstrates the importance of converting Uridine to Ψ in nature, when required. Nothing is by accident. And again, Ψ is part of the natural design.30
Ψ is highly conserved and known to perform essential functions in the cell, several known diseases are associated with defects in RNA pseudouridylation. Also, because pseudouridylation appears to be irreversible, Ψ is usually excreted from the body.31
It is clear that Ψ is important as the ‘fifth nucleotide’ in RNA. It is the most abundant RNA modification with an estimated Ψ/U ratio of 7–9%.32 They are also ubiquitous in tRNAs and facilitate common tRNA structural motifs33 and in particular, Ψs generally localize in the anti-codon stem-loop, in the D stem and, in a conserved fashion, in position 55 of the tRNA.34 This is definitely information that you can use to impress your next date.
Before we forget to remember, there’s a big difference between all things natural as per the design of nature, and forced introduction of in vitro-transcribed mRNAs designed to be transfected into cells for translation of foreign proteins to induce biological activity or immunogenicity for a so-called ‘intended therapeutic effect’. Ψs and m1Ψs are natural and cool and everything, but what about if you introduce billions of them all at once to a cell from an exogenous source like an LNP? That cell very likely won’t know what to do with them. It might even spell doom for the cell- which might be a preferable fate for the organsism. And furthermore, since Ψ is usually at 0.2-0.6% in human mRNA35 as Kevin McKernan also notes here, then perhaps the effects of introducing squawking heaps of m1Ψs might be even more problematic since they’re more a single-celled thing. Let’s revisit a paper in preprint uploaded November 25, 2021, to try to elucidate potential problems with introducing heaps of Ψs or m1Ψs to people.
McKernan et al. pointed out in their timely preprint entitled: “Differences in Vaccine and SARS-CoV-2 Replication Derived mRNA: Implications for Cell Biology and Future Disease”, that “Ψ is also known to create ribosomal frameshifts and it is unclear if m1Ψ will exhibit similar properties”.36
Let’s rewrite that last part.
…it is unclear if m1Ψ will exhibit [ribosomal frameshifts].37
Well. I guess it’s clear now, eh? It’s right there in the title of the Nature paper: N1-methylpseudouridylation of mRNA causes +1 ribosomal frameshifting.
But what is this frameshift thing and why did it happen? Before I get to that, let’s get some more background on the go. By the time this biology lesson is complete, you should be able to answer - without any further guidance - what frameshifting is and why it happens both in the context of codon optimization and in the context of m1Ψ swap ins (if I get to it: transcriptional errors vs. post-transcriptional modifications).
On RNA codons
RNA codons are triplets of the bases A, C, G or U. There are 64 possible codons that correspond to 20 amino acids. Start and stop codons signal the start and stop of translation and take the form of AUG for the start codon, and UAA, UAG or UGA for the stop codons. In Figure 5 below, the short example sequence encodes a peptide 6 amino acids long with start codon AUG (that encodes Methionine) and stop codon UAG. Release factors recognize stop codons, as opposed to tRNAs.

With regard to the modifications of Uridines in the mRNA that encodes the spike protein used in the COVID-19 products, all of the Uridines were substituted out for chemically-modified versions → all 801 of them, in the case of the Pfizer modified mRNA.3839
The claim in the Rapporteur Rolling Review is that the BNT162b2 pro-drug was synthesized in the presence of m1Ψs, but then again, this is the same document where a fake plasmid map was disclosed. I wonder what the effect would be if they subbed-in Ψs and not m1Ψs? I’ll circle back to this.

But for now, just think about the fact that all of the Uridines were replaced. Remember what we said about the Ψ:U ratio being 0.2-0.6% in human mRNA? Based on this, and based on the fact that the spike sequence has 4,284 bases (Figure 7) with 801 of these bases being Uridines, we would expect ~3.2 Ψs to be among these bases. This is what our cells would be used to dealing with. Instead, what we have in reality is 100% m1Ψ content at 18.7% of the total base content.
The modified mRNA spike sequence is shown in Figure 7.40 The m1Ψs are written as Ψs, just to keep with the WHO nomenclature (sorry for potential confusion). I show the sequence as triplets to emphasize the codons. Notice the Poly As at the end. Note that there is a double stop codon, ΨGAΨGA, on the 7th line from the bottom. Perhaps the reason for the consecutive stop codon, as described by Xia et al., is to provide a fail-safe mechanism in the context of the introduction of 801 Ψs, with the hope to reduce the problem of read-throughs if/when the first stop codon fails.41 Moderna also installed this fail-safe mechanism. So you might say, they knew very well that stop codons are more prone to read throughs due to the presence of the Ψ replacements.
When nucleotide U in stop codons was replaced by Ψ, the rate of misreading of a stop codon by near-cognate tRNAs increased.42
McKernan et al. also noted the fail-safe mechanism in the sequence described in the Xia et al. paper, and further point out the presence of an out-of-frame unknown protein AAG23172.1, originally submitted to the GenBank in May 17, 2000 from the National Laboratory For Oncogenes & Related Genes, Shanghai Cancer Institute, 25/Ln 2200 Xie-Tu Road, Shanghai, 200032, P.R. China.
Penultimate to the ΨGA ΨGA stop codon in the BNT162b2 vaccine is an out of frame human amino acid sequence of unknown function (AAG23172.1). Xia et al. also makes note that UGA stop codons are more prone to read through and +1 frameshifts suggesting these mRNA derived stop codons may not be as effective as viral derived stop codons.43
The potential danger for off-target protein production was more than present.
On transfer RNA
tRNA brings amino acids to ribosomes during translation by means of recognizing mRNA codons by their own anti-codon match (cognate aminoacyl-tRNA anticodon–codon). Ribosomes are the machines that link amino acids together to form polypeptide chains as shown in Figure 8. You can also see on the bottom right the date-worthy D, T and anti-codon loops in the tRNA that we talked about.
")
As mentioned, a codon is a triplet of bases made up of any of A, C, G or U. An anti-codon is the complement of a codon. For example, in Figure 8 above, the codon GAG binds the anti-codon CUC/tRNA that is bound to the amino acid Glutamic acid (GLU) (shown in Figure 8 as ‘Amino Acid’). This is because - as we already know as per Watson-Crick - A base-pairs with U and C base-pairs with G. The amino acids are linked by peptide bonds that eventually exit the ribosome for folding. Unfortunately, Watson-Crick rules are not always followed, and this is where we get enter the world of wobbly base-pairing. I will circle back to this.
Translation involves three steps: intitiation, elongation and termination. Intitiation of translation always begins with a start codon: AUG, which codes for the amino acid Methionine in eukaryotes. But how does the ribosome find the start codon to initiate transcription? Initiation of transcription involves sequential complexing of component parts of the ribosome (small and large units), initiator tRNAs and the mRNA. The 5’ cap of the mRNA binds to the small ribosomal unit initiator tRNA complex. The complex then runs along the mRNA from the 5’ end scanning for the start codon. When it finds it, the large ribosomal unit joins to form the translation initiation complex. Translation effectively begins as shown in Figure 9. The ribosome complex pretty much rides the mRNA 5’ to 3’ wave, and the end-product is a chain of amino acids. If it stalls, problems ensue.
 binds to 5' cap of mRNA.
2. Complex scans from 5' to 3' to find the start codon (AUG).
3. Initiator tRNA binds to start codon.
4. Large ribosomal subunit comes together with the mRNA, initiator tRNA, and small ribosomal subunit to form the initiation complex. The initiator tRNA is positioned in the P site of the assembled ribosome.
These steps are assisted by initiation factors (not shown in diagram).")
tRNAs are recruited to the ribosome as ‘required’ per amino acid. As the amino acids form a chain, the chain exits the ribosome where it begins its folding process - even in the absence of chaperones.44 This is something I will elaborate on in another article because it is very important. The way that the chain is produced/fed through/pulled through the ribosome is something of an enigma to me at this point. The link between mRNA misfolding (knots) and initiation of transcription, the kinetic relationship between folding at the exit point of the ribosome, tRNA additions of new amino acids and the type of amino acid and whether or not it is rare45, wobbling, are all deterministic for proper protein production and folding and relate to what might be the most important element of translation → controlled translational velocity.
Translation elongation entails three steps, decoding, peptide bond formation, and tRNA–mRNA translocation, and each step can affect the local rates of translation.46 Specifically, translation rate variation (aka: translational velocity change), is necessary due to things like differences in concentrations of tRNAs carrying rare amino acids like Arginine. In the case of a rare amino acid, translation effectively is put on pause, to wait for the tRNA carrying Arginine to show up. But if something were introduced to the mRNA that induced a pause akin to a stall, then a frameshift would likely ensue. I will elaborate on this when I get to frameshifting.
Another nice visualization of the elongation part of translation is shown in Figure 10. There are 3 grooves that are designed to hold the tRNAs as they enter and leave the ribosome. The Methionine tRNA gets into the P groove first. Groovy. The next coded amino acid will get into the A groove where its cognate codon is ‘exposed’. Ooh lala. Then, a peptide bond is formed between the Methionine and the amino acid attached to the adjacent A groovy tRNA. Naturally, Methionine also lets go of its tRNA. A chain forms. The mRNA then shifts one codon over, and the tRNA in the P groove moves into the E groove for eventual exit from the ribosome. 1, 2, 3. Or rather, A, P, E. APE.

I brought you into this level of detail so that you could start to envision how framshifting might occur. You’re probably getting some great ideas already. Without the concepts of wobbling, or slippery sequences (UUUs or ΨΨΨs - for example), frameshifting wouldn’t happen and this would be a bummer for viruses.47
Sometimes, I take things too literally in biology and I have to remind myself that so many of these schematics and even my own visualizations are merely simplistic depictions of the reality. The danger in this, however, is that the depiction may actually misconstrue the way that something actually works, like frameshifting. A +1 frameshift involves a shift by one base, not by one codon, and considering the potential for near or even non-cognate tRNAs48 getting involved to cause incorporation of aberrant amino acids, the ‘works’ can get even more unclear.
Formally, +1 frameshift errors could originate in either of three ways: in the P-site by transient tRNA unpairing followed by repairing on an overlapping codon (‘slipping’); in the A-site by illegal recruitment of an aminoacyl-tRNA in an incorrect reading frame (‘misframing’); or during translocation of peptidyl-tRNA from the A- to the P-site (‘mistranslocation’). Clearly misframing would have to occur when the ribosomal A-site is available to be filled by aminoacyl-tRNA as the EF-1A ternary complex. But when would slipping be likely to occur.49
Translational velocity can also change due to misfolded mRNAs which can occur when GC content is high. See how I keep repeating this?
Thermodynamically stable elements in the mRNA secondary structure, such as pseudoknots and stem‐loops, are known to slow down ribosome movement along the mRNA, for example at sequences that cause programmed ribosome frameshifting.50515253
But think about this translation thing for a second in the context of the m1Ψs. What will happen at the decoding step when the ribosome tries to decodes a codon with a m1Ψ in it? Or a Ψ in it? Will it recognize these Ψs and m1Ψs as modified Us and seek out an A? Or will it become wobble-errific? Will a simple straight run of m1Ψs induce slippage? Which anti-codon will win out?
It kind of reminds me of the ‘If it fits, I sits?’ meme.
![[Easter edition] 5 Lessons We Should Learn From Cats and Apply in PR](https://substackcdn.com/image/fetch/$s_!IGFp!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F538d2794-695e-4de5-8d81-78cfbe3ce01c_500x373.jpeg "[Easter edition] 5 Lessons We Should Learn From Cats and Apply in PR")
Decoding is a multistep process that entails two major stages, initial selection of ternary complexes before GTP hydrolysis by EF‐Tu and aa‐tRNA accommodation after GTP hydrolysis and release from EF‐Tu–GDP. During the initial selection stage, many different ternary complexes compete for binding to the ribosome, allowing the ribosome to select the aa‐tRNA that is cognate to the mRNA codon.54
The competition for the binding site in the ribosome will ‘take time’ and this relates to what I wrote about the importance of translational velocity. Us do base-pair with As. But again, what will m1Ψs base pair with? Will they be faithful to Watson-Crick to find an A, or wobble their way into a whole new amino acid? Remember what we said about Ψ being promiscuous, similar to Inosine55 (ability to bind A, C, or U)? Ψ can bind all 4 bases. Wouldn’t this necessarily promote differential codon translation? What would happen to the start codons? What would happen to the stop codons? Is it ever the case that the ribosome reads the m1Ψ as a Ψ to seek out any old base? Is the reason for the slippage and frameshifting due to pausing because of the lag time between reading weird-ass m1Ψ-rich codons and seeking out a cognate anti-codon? Keep these questions in mind while we pivot to potential effects on stop codons.
Stop codons are UAA, UAG or UGA as shown in the codon table in Figure 11.

The stop codons for the COVID-19 modified mRNAs would then be ΨAA, ΨAG or ΨGA. (Ψ - m1Ψ as per WHO nomenclature). The manufacturers already anticipated misreading or slippage past these bases in the case of stop codons: this is why they installed the double stop codons as a fail safe. But what if both fail? What if the read is already out of frame? It might seem like I am repeating what I have already said, but I am doing this on purpose because it seems impossible to me that the R&D guys went ahead with this technology knowing that these problems existed. It seems impossible to me because of the implications to human physiology in the in vivo setting: aberrant protein production and misfolded proteins. In fact, the way that the authors of the Nature paper demonstrated frameshifting occurrence was by installing a ‘premature’ stop codon at the interface of the in-frame and +1 frameshifted IVT mRNA sequences. If a frameshift occured upstream of the stop codon, the stop codon would be ineffective and out-of-frame peptides would be produced and this happened only in the context of the m1Ψ as shown below in Figure 12.

There are many ways that the introduction of the m1Ψs could hypothetically induce ribosomal pausing and frameshifting but let’s not forget about other reasons for pausing which also might egg-on frameshifting. Something that I think is going to become more common speak is the idea of misfolded mRNA. I imagine that if there are ‘knots’ in the mRNA, there would be more ribosomal pausing and thus higher frequency of frameshifting.
One major obstacle has been that mRNA molecules are frequently threaded into translating ribosomes, which can only accommodate a single-stranded mRNA.56
This quote implies that the kinks in misfolded mRNAs would slow down the translation since the strand can only be read unkinked. The higher GC content may increase the frequency of mRNA misfolding to increase the likelihood of ribosomal pausing and thus, increase the likelihood of frameshifting. I will leave this subject matter on ‘pause’ for now. Pun intended.
On slippery sequences and frameshifting
A slippery sequence is a short sequence of bases with repeats. An example is UUUAAAC57 although, there are many slippery sequences identified to date.58
These sequences with long repeat bases cause the ribosome to slip past/over codons effectively allowing tRNAs to shift thus changing the reading frame.
Frameshifting occurs when there a shift of any number of nucleotides that is not divisible by 3 in the reading frame [that] will cause subsequent codons to be read differently. This effectively changes the ribosomal reading frame.59
Figure 14 is an illustration of the programmed -1 ribosomal frameshifting signal from HIV-1. This signal consists of a slippery sequence U UUU UUA as underlined.60 HIV (and other viruses) use this as a way to produce mutliple proteins from one mRNA.
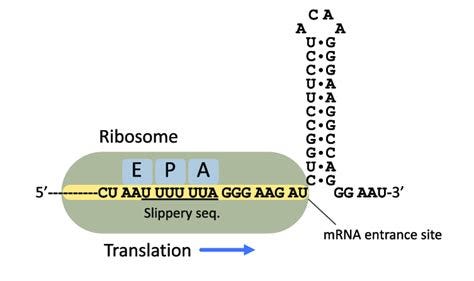
But let’s visualize +1 frameshifting using a photography framing analogy. When you take a photo, the information you would like to convey is in the frame of the photo. We also call this framing in the photographic world. Go figure. It’s like setting the scene to tell a story with the image. In Figure 15, there are two photos. They differ in that I took one step to the left for the photo on the right.

If I were to assign a letter to each object in the frame in the photo on the left, for example, A to the door, C to the wall and G to the longboard, then by taking one step to the left and shifting the frame, when I take a second photo, the longboard is lost! What appears in the frame of the photo instead is a fuse panel (U). Awesome. The triplet of objects in the left photo frame would be ACG (Tyrosine), and the triplet of objects in the right photo frame would be UAC (Threonine). No longboard. I like Threonine better.
Ribosomal frameshifting can happen for any number of reasons and as we have already covered, it can occur when there is a pause to wait for a tRNA carrying a rare amino acid, like Arginine as shown in Figure 16. As we also learned, it can occur due to slippery sequences. Codon optimization that increases GC content also creates ribosomal pausing significant enough to impact proper spike protein folding via frameshifting.61

Here’s another illustration for those of you who can relate frame to phase, so to say. It also illustrates how a kinked mRNA (pseudoknot) or a rare codon can pause the ribosome to induce framshifting in either direction.
The presence of rare codons in mRNAs has well‐documented effects on mRNA stability, accuracy of amino acid incorporation, and protein folding. Rare codons are often found at the boundaries between protein domains, where ribosome pausing is thought to attenuate the vectorial folding of the nascent protein domains, and as a result determine how much correctly folded, soluble protein is present in the cell.626364

And one more image to remind everyone that our infamous m1Ψ causes a frameshifting. Everyone has thown own way to conceptualize so I decided to include many different portrayals of the same concept.

On incomplete protein proteins
I hate to be a Debbie Downer at this point in our exciting journey into the world of translation of weird IVT-produced RNAs, but slippage/read-throughs isn’t the only problem that can ensue when all of the Uridines are swapped out for Ψs in a modified mRNA meant to be encoding the spike protein. It has been documented by the European Medicines Agency that the commercially-available modified mRNAs have low %RNA integrity - hovering around 59%. This means that the average RNA was probably shorter than the original template - capped and tailed and all.

So we’re looking at incomplete codon-optimized mRNA templates with chemically modified Uridines that the ribosome might not read properly or slip over when they are tripled up that likely leads to frameshifting to result in the wrong amino acids being chained together and thus, weird-ass foreign proteins. Say that 5 times fast.
These weird-ass foreign proteins are what some people are referring to as garbage proteins. But you know what? I don’t think this is even the biggest problem. It is a problem, but most of the ‘intended proteins’ are also being translated with high fidelity. If the Uridines were subbed-out for m1Ψs that are not promiscuous, then we have no reason to believe that the ‘intended proteins’ would not be translated if slippery sequences weren’t an issue.
And herein lies even a bigger problem. Hear me out. Or rather, read the following and hear me out again.
Even if there’s 100% fidelity with regard to amino acids, the protein folding might get buggered due to the high GC content which may inducing kinky mRNA. Studies have shown that translation rate is greatly influenced by the GC content of folded structures at the mRNA entry site.65 I know this is a lot to process, but to summarize, I cannot believe they codon-optimized this mRNA and then swapped out all the Us for Ψs and didn’t anticipate aberrant protein production. It’s in their Western Blots. It’s in the EMA documents.66 The manufacturers were told to resolve this. We asked for information on these problems by FOIA request.
Please do read this one too.
I have written a multitude of Substack articles related to amyloids/prion-like proteins, molecular mimicry and autoimmunity in the context of the COVID-19 modified mRNA shots. Not to leave you guys hanging, but I implore you all to keyword search for them and have a quick read. It’s all there. From #blotgate to #plasmidgate and everything in between.
I think I have bombarded you enough with high level reading for today, so I have decided to keep the protein stuff for the next article. But safe to say, my fear is that these shorter RNAs of lower integrity might be getting translated with high fidelity, meaning, that the amyloidogenic peptides are getting translated just fine. My other fear is that off-target proteins are being made in a decent percentage of people who got injected with the COVID-19 shots, and that this may lead to autoimmunity and/or other problems. I also don’t like how the authors claim that off-target transcription is not an issue. It might be. They didn’t check the actual COVID-19 modified mRNAs!
One of the most important concepts to grasp in the context of translation is that it has variable speeds. It’s a dynamic process that depends a lot on the abundance of the specific tRNA that is ‘called for’. Perhaps Rodnina said it best here:
Changes in local translational velocity may alter the fidelity of translation and affect the quality of the protein product, which can result in incorrect or misfolded proteins that have to be removed by the cellular quality control machinery.
These changes can be induced due to codon optimization and/or due to insertion of chemically-modified amino acids.
One thing I would like to comment on here is how absolutely fascinating this all is to me. It seems that the design of the translation process, based on kinetics and thermodynamics, favors proper folding over completeness of protein. The reason I say this is because it seems to me that slipping and frameshifting shouldn’t be possible if the folding part was not more important than the exact amino acids being ascribed to an exact position in the chain, especially those that can fold without the help of chaperones.
I bid you all adieu with a short video where Kevin McKernan talks all about this stuff. Thank you so much for being patient and I really hope I imparted knowledge about frameshifting. Feel free to drop analogies in the comments!
N.B. I am aware that some of my references are repeated. It’s a feature of footnoting in Substack. It is what it is.
Mulroney, T.E., Pöyry, T., Yam-Puc, J.C. et al. N1-methylpseudouridylation of mRNA causes +1 ribosomal frameshifting. Nature (2023). https://doi.org/10.1038/s41586-023-06800-3
Alyssa Cecchetelli. To Codon Optimize or Not: That is the Question. https://blog.addgene.org/to-codon-optimize-or-not-that-is-the-question
Mauro VP, Chappell SA (2014) A critical analysis of codon optimization in human therapeutics. Trends in Molecular Medicine 20:604–613 https://doi.org/10.1016/j.molmed.2014.09.003
Stadler M, Fire A (2011) Wobble base-pairing slows in vivo translation elongation in metazoans. RNA 17:2063–2073 . https://doi.org/10.1261/rna.02890211
S.A. Shabalina, N.A. Spiridonov, A. Kashina. Sounds of silence: synonymous nucleotides as a key to biological regulation and complexity. Nucleic Acids Res., 41 (4) (2013), pp. 2073-2094, 10.1093/nar/gks1205
Stephanie Seneff, Greg Nigh, Anthony M. Kyriakopoulos, Peter A. McCullough, Innate immune suppression by SARS-CoV-2 mRNA vaccinations: The role of G-quadruplexes, exosomes, and MicroRNAs, Food and Chemical Toxicology, Volume 164, 2022, 113008, ISSN 0278-6915, https://doi.org/10.1016/j.fct.2022.113008
B. Herdy, C. Mayer, D. Varshney, G. Marsico, P. Murat, C. Taylor, C. D'Santos, D. Tannahill, S. Balasubramanian. Analysis of NRAS RNA G-quadruplex binding proteins reveals DDX3X as a novel interactor of cellular G-quadruplex containing transcripts. Nucleic Acids Res., 46 (21) (2018), pp. 11592-11604, 10.1093/nar/gky861
McKernan, K., Kyriakopoulos, A. M., & McCullough, P. A. (2021, November 25). Differences in Vaccine and SARS-CoV-2 Replication Derived mRNA: Implications for Cell Biology and Future Disease. https://doi.org/10.31219/osf.io/bcsa6
Park, J.W., Lagniton, P.N.P., Liu, Y., Xu, R.H. (2021). mRNA vaccines for COVID-19: what, why and how. International Journal of Biological Sciences, 17(6), 1446-1460. https://doi.org/10.7150/ijbs.59233
Katsnelson, A. (2011). Breaking the silence. Nature Medicine, 17(12), 1536–1538. doi:10.1038/nm1211-1536
Bartoszewski RA, Jablonsky M, Bartoszewska S, Stevenson L, Dai Q, Kappes J, Collawn JF, Bebok Z. A synonymous single nucleotide polymorphism in DeltaF508 CFTR alters the secondary structure of the mRNA and the expression of the mutant protein. J Biol Chem. 2010 Sep 10;285(37):28741-8. doi: 10.1074/jbc.M110.154575. Epub 2010 Jul 13. PMID: 20628052; PMCID: PMC2937902
Chamary JV, Parmley JL, Hurst LD. Hearing silence: non-neutral evolution at synonymous sites in mammals. Nat Rev Genet. 2006 Feb;7(2):98-108. doi: 10.1038/nrg1770. PMID: 16418745
Xia X. Detailed Dissection and Critical Evaluation of the Pfizer/BioNTech and Moderna mRNA Vaccines. Vaccines (Basel). 2021 Jul 3;9(7):734. doi: 10.3390/vaccines9070734. PMID: 34358150; PMCID: PMC8310186
https://en.wikipedia.org/wiki/Pseudouridine
Jonas Cerneckis, Qi Cui, Chuan He, Chengqi Yi, Yanhong Shi, Decoding pseudouridine: an emerging target for therapeutic development, Trends in Pharmacological Sciences, Volume 43, Issue 6, 2022, Pages 522-535, ISSN 0165-6147, https://doi.org/10.1016/j.tips.2022.03.008
Adachi H., Hengesbach M., Yu Y.-T., Morais P. (2021). From Antisense RNA to RNA Modification: Therapeutic Potential of RNA-Based Technologies. Biomedicines 9, 550. 10.3390/biomedicines9050550
Morais P, Adachi H, Yu YT. The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines. Front Cell Dev Biol. 2021 Nov 4;9:789427. doi: 10.3389/fcell.2021.789427. PMID: 34805188; PMCID: PMC8600071
Spenkuch F, Motorin Y, Helm M. Pseudouridine: still mysterious, but never a fake (uridine)! RNA Biol. 2014;11(12):1540-54. doi: 10.4161/15476286.2014.992278. PMID: 25616362; PMCID: PMC4615568
Hudson GA, Bloomingdale RJ, Znosko BM. Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides. RNA 2013; 19:1474-82; PMID:24062573; http://dx.doi.org/ 10.1261/rna.039610.113
Kierzek E, Malgowska M, Lisowiec J, Turner DH, Gdaniec Z, Kierzek R. The contribution of pseudouridine to stabilities and structure of RNAs. Nucleic acids research 2013; 42:3492-501; PMID:24369424; http://dx.doi.org/ 10.1093/nar/gkt1330
https://en.wikipedia.org/wiki/N1-Methylpseudouridine
Wurm JP, Griese M, Bahr U, Held M, Heckel A, Karas M, et al. (March 2012). "Identification of the enzyme responsible for N1-methylation of pseudouridine 54 in archaeal tRNAs". RNA. 18 (3): 412–420. doi:10.1261/rna.028498
Svitkin Y. V., Cheng Y. M., Chakraborty T., Presnyak V., John M., Sonenberg N. (2017). N1-methyl-pseudouridine in mRNA Enhances Translation through eIF2α-dependent and Independent Mechanisms by Increasing Ribosome Density. Nucleic Acids Res. 45, 6023–6036. 10.1093/nar/gkx135
Schwartz S., Bernstein D. A., Mumbach M. R., Jovanovic M., Herbst R. H., León-Ricardo B. X., et al. (2014). Transcriptome-wide Mapping Reveals Widespread Dynamic-Regulated Pseudouridylation of ncRNA and mRNA. Cell 159, 148–162. 10.1016/j.cell.2014.08.028
Morais P, Adachi H, Yu YT. The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines. Front Cell Dev Biol. 2021 Nov 4;9:789427. doi: 10.3389/fcell.2021.789427. PMID: 34805188; PMCID: PMC8600071
Parr C. J. C., Wada S., Kotake K., Kameda S., Matsuura S., Sakashita S., et al. (2020). N 1-Methylpseudouridine Substitution Enhances the Performance of Synthetic mRNA Switches in Cells. Nucleic Acids Res. 48, e35. 10.1093/nar/gkaa070
Charette M., Gray M.W. Pseudouridine in RNA: What, where, how, and why. IUBMB Life. 2000;49:341–351. doi: 10.1080/152165400410182
Hayrapetyan A., Seidu-larry S., Helm M. Function of Modified Nucleosides in RNA Stabilization. In: Grosjean H., editor. Structure Mechanism, Functions, Cellular Interactions and Evolution. Landes Bioscience; Austin, TX, USA: 2009. pp. 550–563
Borchardt EK, Martinez NM, Gilbert WV. Regulation and Function of RNA Pseudouridylation in Human Cells. Annu Rev Genet. 2020 Nov 23;54:309-336. doi: 10.1146/annurev-genet-112618-043830. Epub 2020 Sep 1. PMID: 32870730; PMCID: PMC8007080
Penzo M, Guerrieri AN, Zacchini F, Treré D, Montanaro L. RNA Pseudouridylation in Physiology and Medicine: For Better and for Worse. Genes (Basel). 2017 Nov 1;8(11):301. doi: 10.3390/genes8110301. PMID: 29104216; PMCID: PMC5704214
Morais P, Adachi H, Yu YT. The Critical Contribution of Pseudouridine to mRNA COVID-19 Vaccines. Front Cell Dev Biol. 2021 Nov 4;9:789427. doi: 10.3389/fcell.2021.789427. PMID: 34805188; PMCID: PMC8600071
Xiaoyu Li, Shiqing Ma, Chengqi Yi, Pseudouridine: the fifth RNA nucleotide with renewed interests, Current Opinion in Chemical Biology, Volume 33, 2016, Pages 108-116, ISSN 1367-5931, https://doi.org/10.1016/j.cbpa.2016.06.014
https://en.wikipedia.org/wiki/Pseudouridine
Roovers M., Hale C., Tricot C., Terns M., Terns R., Grosjean H., Droogmans L. Formation of the conserved pseudouridine at position 55 in archaeal tRNA. Nucleic Acids Res. 2006;34:4293–4301. doi: 10.1093/nar/gkl530
Li X., Zhu P., Ma S., Song J., Bai J., Sun F., Yi C. Chemical pulldown reveals dynamic pseudouridylation of the mammalian transcriptome. Nat. Chem. Biol. 2015;11:592–597. doi: 10.1038/nchembio.1836
McKernan, K., Kyriakopoulos, A. M., & McCullough, P. A. (2021, November 25). Differences in Vaccine and SARS-CoV-2 Replication Derived mRNA: Implications for Cell Biology and Future Disease. https://doi.org/10.31219/osf.io/bcsa6
https://en.wikipedia.org/wiki/N1-Methylpseudouridine
“The RNA does not contain any uridines; instead of uridine the modified N1-methylpseudouridine is used in RNA synthesis.” Rapporteur Rolling Review critical assessment report
https://berthub.eu/articles/posts/reverse-engineering-source-code-of-the-biontech-pfizer-vaccine/
Xia, X. Detailed Dissection and Critical Evaluation of the Pfizer/BioNTech and Moderna mRNA Vaccines. Vaccines 2021, 9, 734. https://doi.org/10.3390/vaccines9070734
Xia, X. Detailed Dissection and Critical Evaluation of the Pfizer/BioNTech and Moderna mRNA Vaccines. Vaccines 2021, 9, 734. https://doi.org/10.3390/vaccines9070734
McKernan, K., Kyriakopoulos, A. M., & McCullough, P. A. (2021, November 25). Differences in Vaccine and SARS-CoV-2 Replication Derived mRNA: Implications for Cell Biology and Future Disease. https://doi.org/10.31219/osf.io/bcsa6
Victor Marchenkov et al., In Vivo Incorporation of Photoproteins into GroEL Chaperonin Retaining Major Structural and Functional Properties, Molecules, 28, 4, (1901), (2023).
Davyt M, Bharti N, Ignatova Z. Effect of mRNA/tRNA mutations on translation speed: Implications for human diseases. J Biol Chem. 2023 Sep;299(9):105089. doi: 10.1016/j.jbc.2023.105089. Epub 2023 Jul 24. PMID: 37495112; PMCID: PMC10470029
Rodnina MV. The ribosome in action: Tuning of translational efficiency and protein folding. Protein Sci. 2016 Aug;25(8):1390-406. doi: 10.1002/pro.2950. Epub 2016 Jun 8. PMID: 27198711; PMCID: PMC4972197
Martina M Yordanova & Pavel V Baranov. (2022). Viruses: A frameshift in time. eLife 11:e78373. https://doi.org/10.7554/eLife.78373
Plant EP, Nguyen P, Russ JR, Pittman YR, Nguyen T, Quesinberry JT, Kinzy TG, Dinman JD. Differentiating between near- and non-cognate codons in Saccharomyces cerevisiae. PLoS One. 2007 Jun 13;2(6):e517. doi: 10.1371/journal.pone.0000517. PMID: 17565370; PMCID: PMC1885216
Farabaugh, P.J. and Björk, G.R. (1999), How translational accuracy influences reading frame maintenance. The EMBO Journal, 18: 1427-1434. https://doi.org/10.1093/emboj/18.6.1427
Caliskan N, Katunin VI, Belardinelli R, Peske F, Rodnina MV (2014) Programmed −1 frame shifting by kinetic partitioning during impeded translocation. Cell 157:1619–1631
Kim HK, Liu F, Fei J, Bustamante C, Gonzalez RL Jr, Tinoco I Jr (2014) A frame shifting stimulatory stem loop destabilizes the hybrid state and impedes ribosomal translocation. Proc Natl Acad Sci USA 111:5538–5543
Chen J, Petrov A, Johansson M, Tsai A, O'Leary SE, Puglisi JD (2014) Dynamic pathways of −1 translational frame shifting. Nature 512:328–332
Rodnina MV. The ribosome in action: Tuning of translational efficiency and protein folding. Protein Sci. 2016 Aug;25(8):1390-406. doi: 10.1002/pro.2950. Epub 2016 Jun 8. PMID: 27198711; PMCID: PMC4972197
Rodnina MV. The ribosome in action: Tuning of translational efficiency and protein folding. Protein Sci. 2016 Aug;25(8):1390-406. doi: 10.1002/pro.2950. Epub 2016 Jun 8. PMID: 27198711; PMCID: PMC4972197
Licht K, Hartl M, Amman F, Anrather D, Janisiw MP, Jantsch MF. Inosine induces context-dependent recoding and translational stalling. Nucleic Acids Res. 2019 Jan 10;47(1):3-14. doi: 10.1093/nar/gky1163. PMID: 30462291; PMCID: PMC6326813
Gongwang Yu, Hanbing Zhu, Xiaoshu Chen, Jian-Rong Yang, Specificity of mRNA Folding and Its Association with Evolutionarily Adaptive mRNA Secondary Structures, Genomics, Proteomics & Bioinformatics, Volume 19, Issue 6, 2021, Pages 882-900, ISSN 1672-0229, https://doi.org/10.1016/j.gpb.2019.11.013
https://www.wikiwand.com/en/Slippery_sequence
Brierley I, Jenner AJ, Inglis SC. Mutational analysis of the "slippery-sequence" component of a coronavirus ribosomal frameshifting signal. J Mol Biol. 1992 Sep 20;227(2):463-79. doi: 10.1016/0022-2836(92)90901-u. PMID: 1404364; PMCID: PMC7125858
https://en.wikipedia.org/wiki/Ribosomal_frameshift
Chang KC, Wen JD. Programmed -1 ribosomal frameshifting from the perspective of the conformational dynamics of mRNA and ribosomes. Comput Struct Biotechnol J. 2021 Jun 14;19:3580-3588. doi: 10.1016/j.csbj.2021.06.015. PMID: 34257837; PMCID: PMC8246090
McKernan, K., Kyriakopoulos, A. M., & McCullough, P. A. (2021, November 25). Differences in Vaccine and SARS-CoV-2 Replication Derived mRNA: Implications for Cell Biology and Future Disease. https://doi.org/10.31219/osf.io/bcsa6
Presnyak V, Alhusaini N, Chen YH, Martin S, Morris N, Kline N, Olson S, Weinberg D, Baker KE, Graveley BR, Coller J (2015) Codon optimality is a major determinant of mRNA stability. Cell 160:1111–1124
Boel G, Letso R, Neely H, Price WN, Wong KH, Su M, Luff JD, Valecha M, Everett JK, Acton TB, Xiao R, Montelione GT, Aalberts DP, Hunt JF (2016) Codon influence on protein expression in E. coli correlates with mRNA levels. Nature 529:358–363
Mishima Y, Tomari Y (2016) Codon usage and 3' UTR length determine maternal mRNA stability in zebrafish. Mol Cell 61:874–885
Qu X, Wen JD, Lancaster L, Noller HF, Bustamante C, Tinoco I Jr. (2011) The ribosome uses two active mechanisms to unwind messenger RNA during translation. Nature 475:118–121
Tinari S. The EMA covid-19 data leak, and what it tells us about mRNA instability BMJ 2021; 372 :n627 doi:10.1136/bmj.n627
Awesome post!
That double ΨGA ΨGA stop codon as "failsafe" doesn't make sense to me. They're in the *same frame*. So a +1 frameshift could actually read AΨG, starting off on a new tangent. Geeze, I stew for days sometimes on software design, trying to avoid "clever" tricks that might blow up on me, and nothing I'm working on lately endangers anyone in the slightest. What were these "geniuses" thinking anyway?